DistributedLog
DistributedLog began its life as a separate project under the Apache Foundation. It was merged into BookKeeper in 2017.
The DistributedLog API is an easy-to-use interface for managing BookKeeper entries that enables you to use BookKeeper without needing to interact with ledgers directly.
DistributedLog (DL) maintains sequences of records in categories called logs (aka log streams). Writers append records to DL logs, while readers fetch and process those records.
Architecture
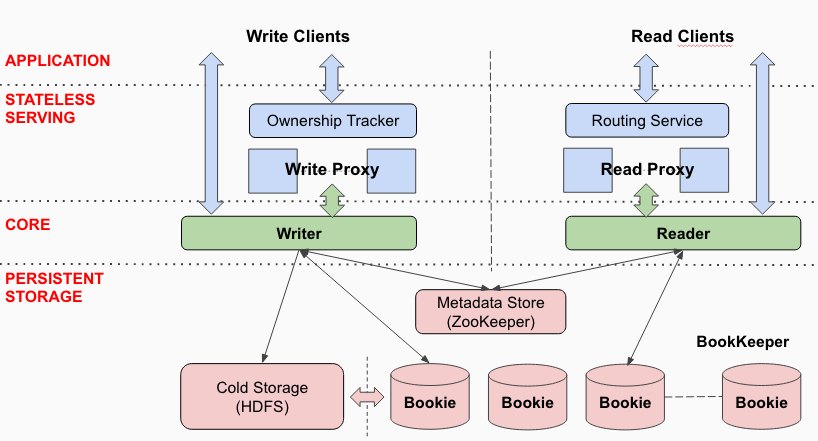
The diagram below illustrates how the DistributedLog API works with BookKeeper:
Logs
A log in DistributedLog is an ordered, immutable sequence of log records.
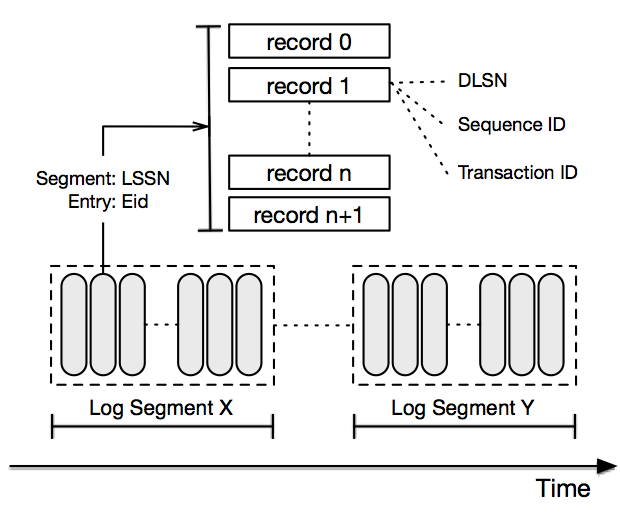
The diagram below illustrates the anatomy of a log stream:
Log records
Each log record is a sequence of bytes. Applications are responsible for serializing and deserializing byte sequences stored in log records.
Log records are written sequentially into a log stream and assigned with a a unique sequence number called a DLSN (DistributedLog Sequence Number).
In addition to a DLSN, applications can assign their own sequence number when constructing log records. Application-defined sequence numbers are known as TransactionIDs (or txid). Either a DLSN or a TransactionID can be used for positioning readers to start reading from a specific log record.
Log segments
Each log is broken down into log segments that contain subsets of records. Log segments are distributed and stored in BookKeeper. DistributedLog rolls the log segments based on the configured rolling policy, which be either
- a configurable period of time (such as every 2 hours), or
- a configurable maximum size (such as every 128 MB).
The data in logs is divided up into equally sized log segments and distributed evenly across bookies. This allows logs to scale beyond a size that would fit on a single server and spreads read traffic across the cluster.
Namespaces
Log streams that belong to the same organization are typically categorized and managed under a namespace. DistributedLog namespaces essentially enable applications to locate log streams. Applications can perform the following actions under a namespace:
- create streams
- delete streams
- truncate streams to a given sequence number (either a DLSN or a TransactionID)
Writers
Through the DistributedLog API, writers write data into logs of their choice. All records are appended into logs in order. The sequencing is performed by the writer, which means that there is only one active writer for a log at any given time.
DistributedLog guarantees correctness when two writers attempt to write to the same log when a network partition occurs using a fencing mechanism in the log segment store.
Write Proxy
Log writers are served and managed in a service tier called the Write Proxy (see the diagram above). The Write Proxy is used for accepting writes from a large number of clients.
Readers
DistributedLog readers read records from logs of their choice, starting with a provided position. The provided position can be either a DLSN or a TransactionID.
Readers read records from logs in strict order. Different readers can read records from different positions in the same log.
Unlike other pub-sub systems, DistributedLog doesn't record or manage readers' positions. This means that tracking is the responsibility of applications, as different applications may have different requirements for tracking and coordinating positions. This is hard to get right with a single approach. Distributed databases, for example, might store reader positions along with SSTables, so they would resume applying transactions from the positions store in SSTables. Tracking reader positions could easily be done at the application level using various stores (such as ZooKeeper, the filesystem, or key-value stores).
Read Proxy
Log records can be cached in a service tier called the Read Proxy to serve a large number of readers. See the diagram above. The Read Proxy is the analogue of the Write Proxy.
Guarantees
The DistributedLog API for BookKeeper provides a number of guarantees for applications:
- Records written by a writer to a log are appended in the order in which they are written. If a record R1 is written by the same writer as a record R2, R1 will have a smaller sequence number than R2.
- Readers see records in the same order in which they are written to the log.
- All records are persisted on disk by BookKeeper before acknowledgements, which guarantees durability.
- For a log with a replication factor of N, DistributedLog tolerates up to N-1 server failures without losing any records.
API
Documentation for the DistributedLog API can be found here.
At a later date, the DistributedLog API docs will be added here.